Caffiene Cache Design Review
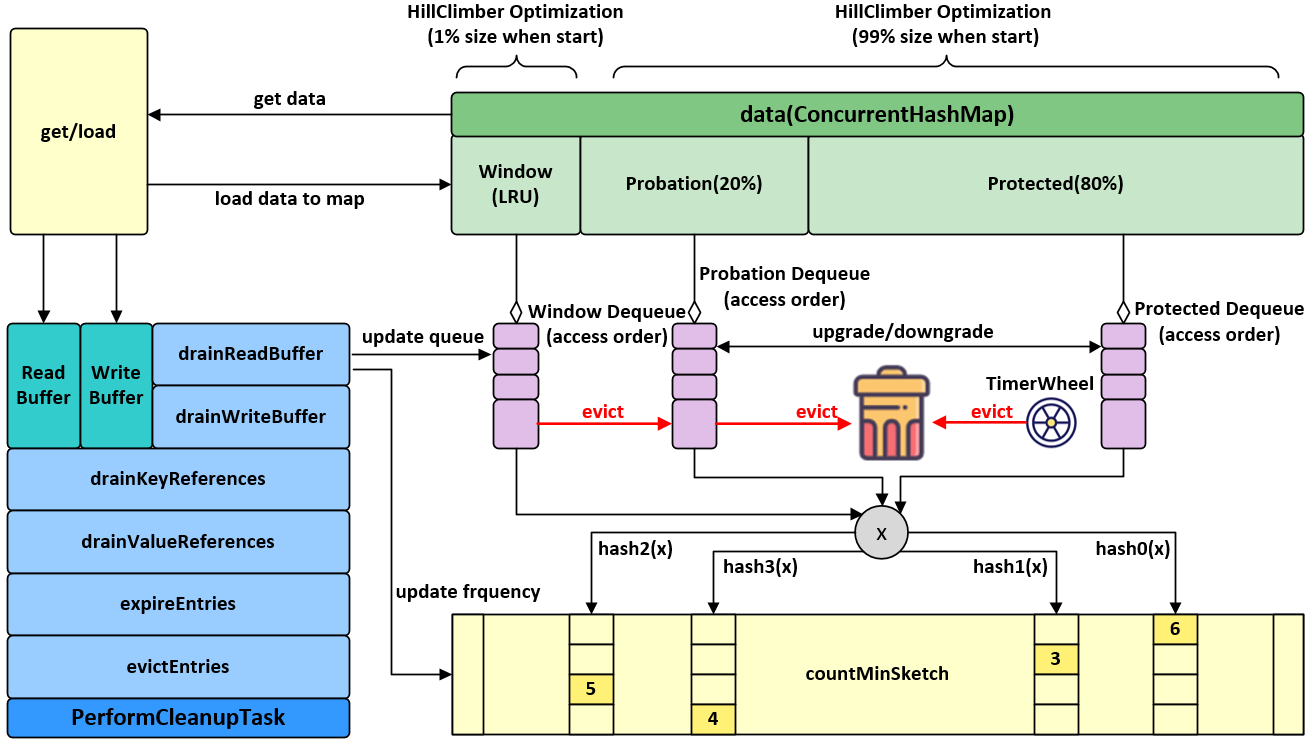
카페인 캐시는 Java 기반 고성능 인메모리 캐시 라이브러리다. 효율적인 cache management와 eviction policy를 지원한다. 카페인 캐시의 설계를 살펴보자.
WTiny LFU
WTiny FLU는 LRU를 사용하는 3개의 Doublely Linked List(DLL) 과 Count Min-Sketch, Hill Climbing Algorithm을 통해 이루어진다. WTiny LFU를 살펴보기 전에 WTiny LFU 논문에서 제시하는 기존 Cache Policy 들의 단점을 살펴보자.
WTiny LFU 논문에서는 기존 LRU + frequency 조합의 알고리즘들인 ARC, LIRS 등에 대해 지적하고 있는 부분이 ghost entry problem이다. 이 문제를 살펴보기 위해 ARC 알고리즘을 먼저 살펴보자.
Adaptive replacement cache Algorithm
ARC(Adaptive replacement cache) 알고리즘은 기본적으로 4개의 영역으로 구분된다.
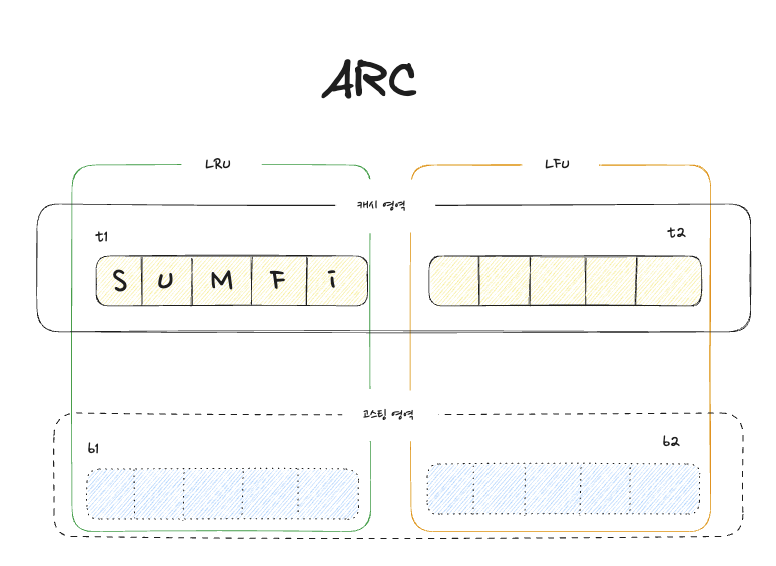
- 1번 hit 한 데이터들이 포함된 t1 영역
- 2번 이상 hit한 데이터들이 포함된 t2 영역
- 1번 hit 한 데이터들이 밀려나와 frequency만 들고있는 b1 영역
- 2번 이상 hit 한 데이터들이 밀려나와 frequency만 들고있는 b1 영역
최초 ARC 논문에는 T2, B2 영역도 LRU를 사용했으나, 여러 변형에 대한 연구와 논문으로 인해 요즘은 LFU를 사용하는 추세다. 5가지 시나리오를 통해 ARC 알고리즘이 어떻게 동작하는지 확인해보자.
캐시된적 없는 데이터의 추가
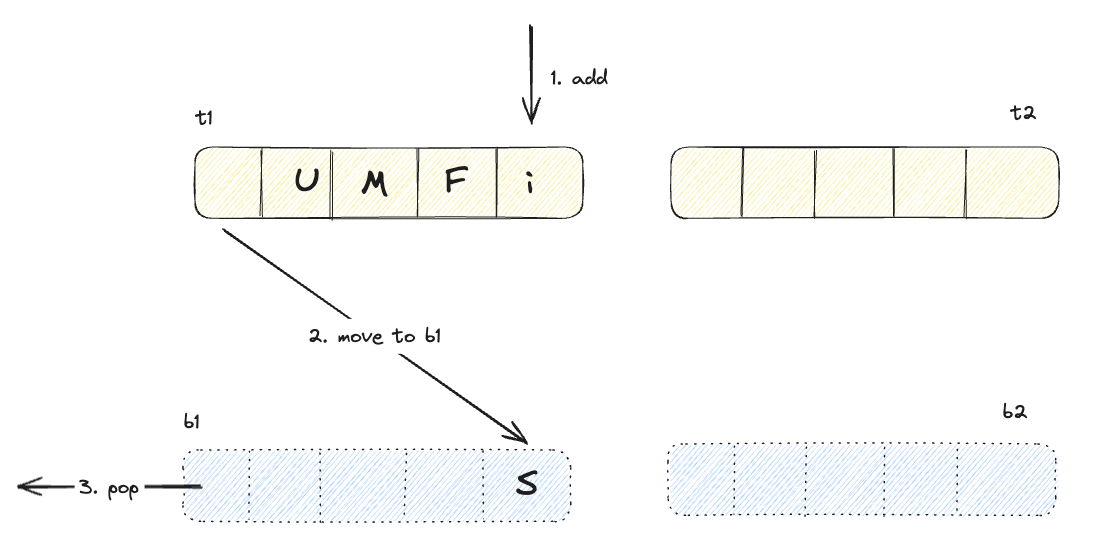
t1 영역에서 hit
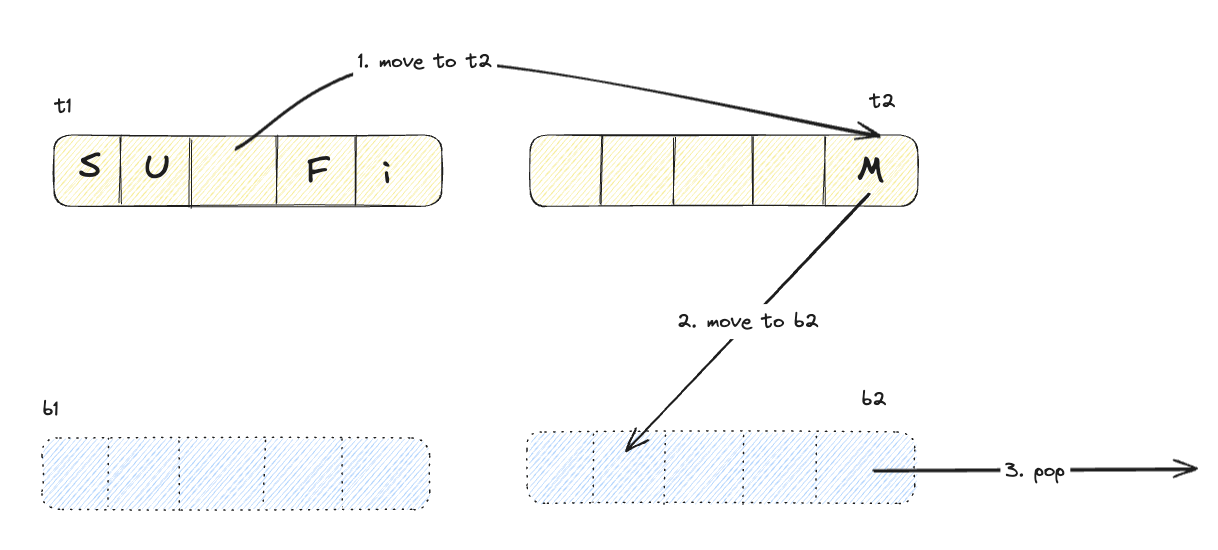
t2 영역에서 hit
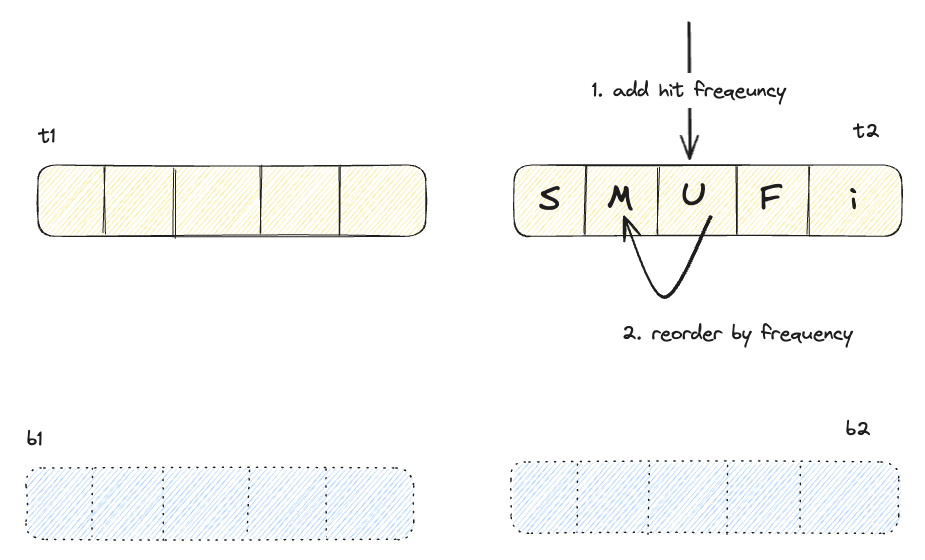
b1 영역에서 hit
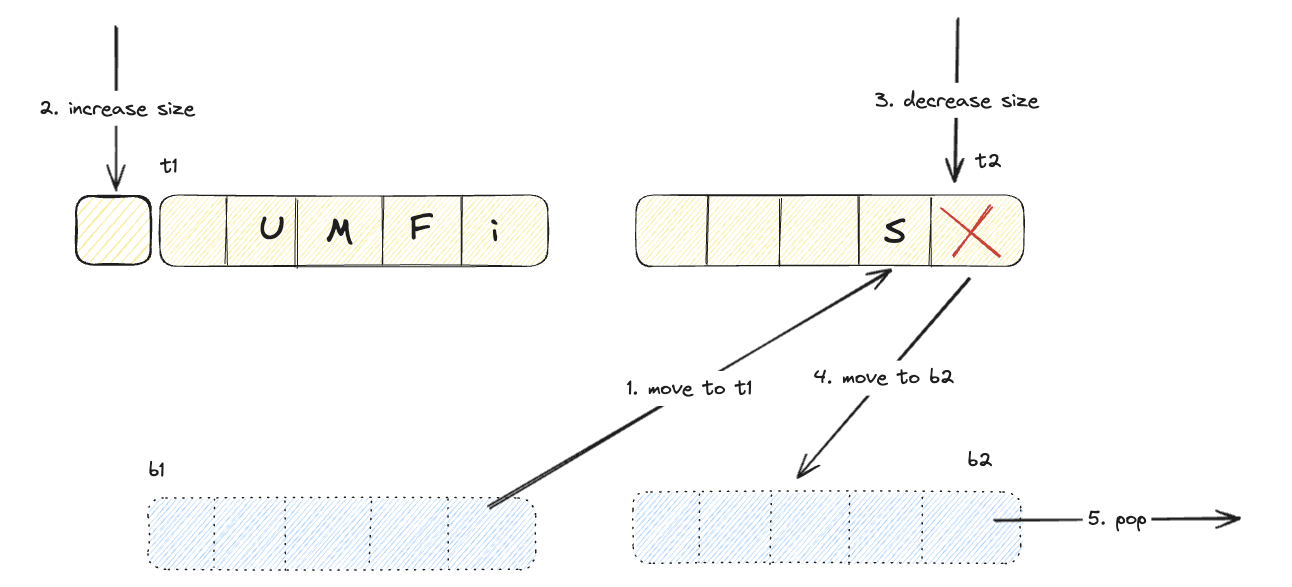
b2 영역에서 hit
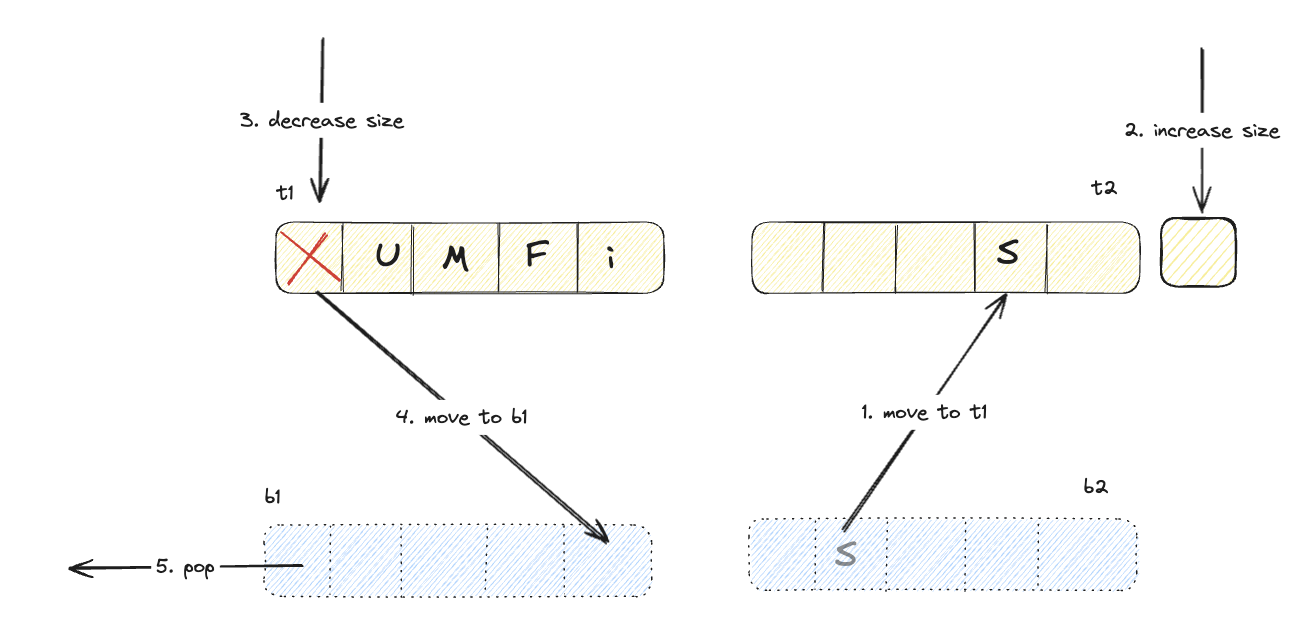
위 다이어그램에서 알 수 있듯이 고스팅 영역에서 hit된 데이터는, 실질적 데이터는 없고 frequency만 담고 있지만, 복구되면서 해당 frequency를 사용하며 적절한 영역에 추가된다. 또한 어느 영역(b1, b2)에서 검색 되었는지에 따라서 라이브 영역의 크기를 동적으로 변화시킨다. 이런 특성으로 ARC는 access pattern에 대한 recency bias를 보장한다.
다만 WTiny LFU 논문에서 이야기하고자 하는 바는 이런 특질을 가지는 알고리즘들이 LFU의 특성과 recency bias를 잘 반영하기 위해 ghosting과 frequency를 entry 마다 저장해야한다는 점이다.
How WTiny LFU Works?
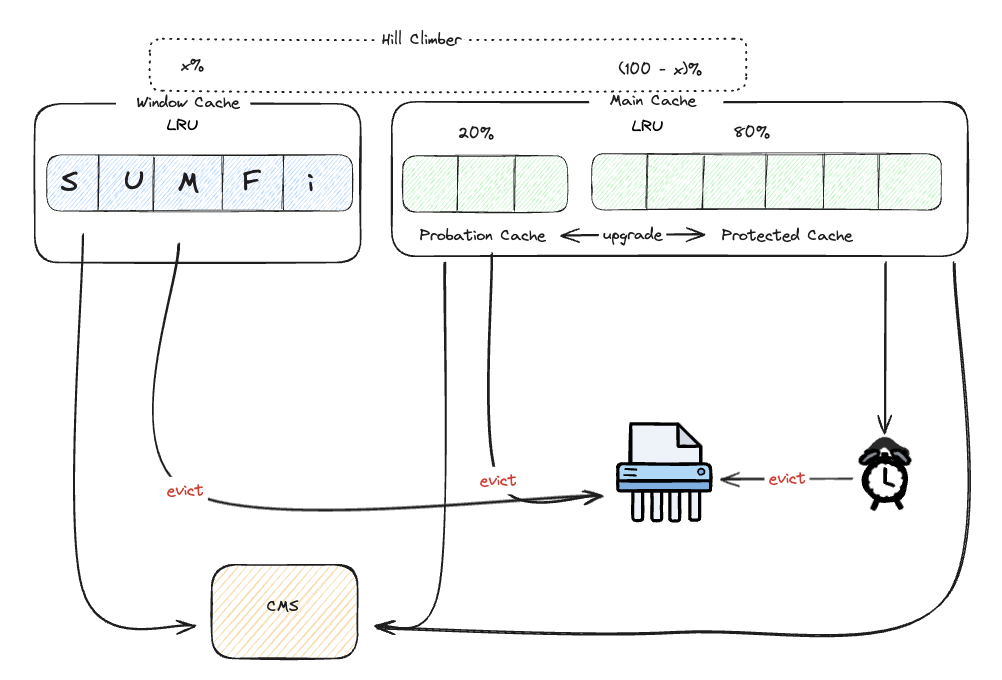
WTiny LFU는 크게 두 영역으로 나뉜다. 신규 엔트리를 위한 Window Cache 와 long lived entry 를 위한 Main Cache 역영이다. Main Cache 영역은 내부에서 2:8 비율로 Probation Cache 와 Protected Cache로 나뉘어서 관리된다.
Window Cache는 최근에 반영된 데이터들은 거의 대부분 낮은 frequency count를 가지고 있기 때문에 일정 기간 엔트리의 가치를 높이기 위해 Window Cache 영역으로 추가된다. 이는 entry의 popularity가 높아질 때 연속적인 cache miss를 방지하기 위한 조치다. Window Cache에 크기가 가득 차서 eviction이 발생하게 되면 Main Cache로 이동한다.
Eviction Policy
Window Cache entry를 이동해야할 때 Main Cache 영역이 가득 차 있지 않다면 Window Cache entry를 Main Cache로 이동해도 문제가 되지 않는다. 문제가 되는 경우는 Main Cache가 가득 차 있는 경우다. 이때는 어느 데이터가 적중률이 높을지, 즉 다시 사용될 가능성이 높을지에 대해 예측해야 한다. 이 때 CMS를 사용하게 된다. Window Cache candidate entry와 Probation Cache candidate entry중 frequency가 높은 데이터가 승리한다.
만약 Cache entry의 TTL이 만료되어 제거되어야 하는 경우는 어떨까? 이 문제를 효율적으로 해결하기 위해 HTW를 사용한다. HTW를 통해 O(1)의 속도로 제거되어야할 entry를 검색해 데이터를 제거함으로써 TTL에 의한 eviction을 효율적으로 구현한다.
WTiny LFU는 Main Cache의 장기 보존을 위해 Segmented LRU 정책을 사용한다. Probation Cache부터 시작해 액세스가 된 entry는 Protection Cache로 승격하는 구조다. 물론 Protection Cache가 가득 차면 Protection Cache entry를 강등시킨다.
이 모든 Cache entry는 DLL을 사용하는 간단한 LRU구조로 관리되기 때문에 빠른 속도로 데이터 처리가 가능하다.
Adaptivity
Window Cache와 Main Cache 영역의 크기는 어떻게 결정될까? 우리는 매 시간 변화하는 트래픽 성질을 가지고 있다. 쉽게 말해 아침에 수신하는 액세스 패턴과 저녁에 수신하는 액세스 패턴이 다를 수 있다는 이야기다. 이 경우에 따라 높은 캐시 적중률을 위해 Window Cache와 Main Cache 간의 균형을 찾아야 한다. 즉, 워크로드의 빈도를 통해 최신성을 편향하는 결과값을 도출해 내야 하는 작업을 수행해야 한다. 또한 이런 작업을 매번 하드코딩하거나, 수동으로 사람의 개입을 통해 해결하기란 매우 어렵고 손이 많이 가는 영역이다.
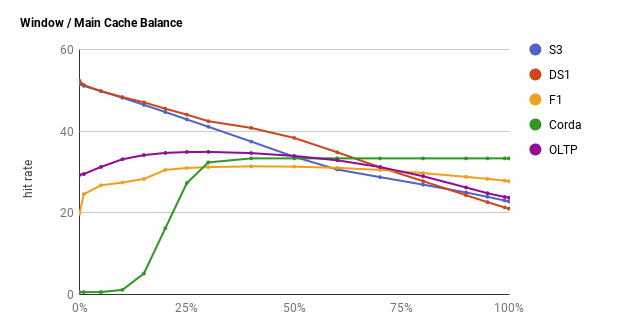
이 균형을 조정하기 위해 카페인 캐시는 Hill Climing Algorithm을 채용한다. 일종의 간단한 이진 탐색 기법인데, PS에서 사용하는 global optima를 위한 binary search가 아닌 local optima를 가볍고 빠르게 탐색하기 위한 알고리즘이다. 이를 통해 동적으로 두 Cache 간의 최적 균형을 찾아 조율한다.
HashDoS protection
카페인 캐시는 내부적으로 엔트리를 관리하기 위해 key의 hash code를 사용한다. 이 때 문제가 되는 것은 key의 hash code가 충돌하는 현상인데, 이로 인해 성능이 저하될 수 있다. 이 문제를 해결하기 위해 내부적으로 해시 테이블에서 RB-Tree를 사용해 문제를 완화시킨다.

CMS에서는 어떨까? CMS 또한 space compect하고 time complexity가 훌륭한 자료구조지만, 블룸 필터와 동일하게 false positive한 성질을 피해갈 수 없다. 즉, 오탐이 발생할 확률이 있는데 이 문제로 인해 잘못된 victim entry를 제거할 가능성이 있다. 이 문제에 대한 해결책은 소량의 jitter를 도입해 제거에 대한 판단을 비결정적으로 만드는 것이다. 내부에서는 비 결정적 판단을 위해 임계값과 random sampling을 사용한다.
1 | public boolean admit(long candidateKey, long victimKey) { |
Ring Buffer
캐시는 히트가 발생하면 오브젝트에 락을 걸고 해당 객체를 다시 정렬한다. LRU는 락을 걸고 엔트리를 head로 리프로모팅, LFU는 재정렬하는 방식이다. 이런 특성으로 인해 매 액세스 마다 객체에 lock이 걸리는데 이는 캐시 시스템에서 발생하는 병목 지점중 하나다. Facebook의 Rocks DB도 이 문제를 Rocks의 병목 포인트로 지목하고 개선하기도 했다.
카페인 캐시 또한 마찬가지다. 캐시 히트에 대한 처리를 위해 매번 엔트리에 락을 걸고 작업을 해야하는데, 이 문제를 해결할 아이디어를 database의 WAL(write ahead log)에서 채용한다.
Read Buffer
카페인 캐시의 Read buffer는 Stripe Ring Buffer로 구현된다. Stripe는 경합을 줄이는 데 사용되며, Stripe의 선택은 요청 thread id의 hash 값을 사용해 선택한다. 또한 Buffer 이기 때문에 변경 사항을 즉시 반영하지 않고, 추후 버퍼가 가득 찼을 때 일괄 반영을 수행한다. Read Buffer에 쌓이는 데이터는 eviction policy의 적중률을 최적화하는데 사용되므로 약간의 손실을 허용하며 데이터를 적재한다.
Write Buffer
Write buffer 또한 Stripe Ring Buffer로 구현된다. 다만 아주 중요한 점은 Read Buffer와 다르게 쓰기에 대한 작업은 손실되어선 안된다는 것이다. 따라서 버퍼를 채워질 때마다 반영하게 되는데, 이 작업에 대한 우선순위가 높기 때문에 일반적으로 쓰기 버퍼는 비어 있거나 매우 작은 상태로 유지되곤한다.
각 쓰기 / 읽기 버퍼들의 동작에서 볼 수 있듯이, 기존 캐시는 작은 양의 작업을 수행하기 위해 각 작업을 잠그는 반면, 카페인 캐시는 작업을 일괄 처리하고 그 비용을 여러 스레드에 분산시킨다. 이를 통해 잠금 경합의 비용을 없애고 잠금에 따른 패널티를 상각시킨다.
또한 Read buffer 일괄 처리의 장점은 잠금의 베타적 특성으로 인해 버퍼가 주어진 시간에 단일 스레드에서만 소진된다는 점이다. 이를 통해 효율적인 multi-producer / single-consumer 기반 버퍼를 구현할 수 있고, Ring Buffer의 특성상 CPU 캐시 효율을 높히는 하드웨어 메모리 구조에 적합하다.
Summary
카페인 캐시를 구성하는 주요 알고리즘과 컴포넌트들에 대해 이야기했다. WTiny LFU가 ARC, LIRS가 가지는 문제점을 개선하는 방식, Hill Climing Algorithm으로 변화하는 액세스 패턴에 따라 효율적인 Cache Area Ratio를 계산하는 기법, HashDOS 문제를 대응하는 방법과 Stripe Ring Buffer를 통해 전통적 캐시 시스템의 lock overhead를 완화하는 방법에 대해 살펴봤다. 마무리로 카페인 캐시의 디자인 다이어그램을 첨부하며 이 글을 마친다.