
Distribution Layer
Distribution layer는 클러스터 데이터의 통합 뷰를 제공한다.
Overview
어느 노드에서나 클러스터의 모든 데이터에 액세스할 수 있도록 하기 위해 KV 쌍의 모놀리식 정렬된 맵에 데이터를 저장한다. 이 키 공간은 클러스터의 모든 데이터와 그 위치를 설명하며, 모든 키를 항상 단일 범위에서 찾을 수 있도록 키 공간의 연속적인 청크인 “range”로 분할한다.
Cockroach DB는 sorted map을 구현해 이를 활성화한다.
- Simple lookups : 데이터의 특정 부분을 담당하는 노드를 식별하기 때문에 쿼리는 원하는 데이터를 찾을 수 있는 위치를 빠르게 찾을 수 있다.
- Efficient scans : 데이터의 순서를 정의하면 스캔 중에 특정 범위 내의 데이터를 쉽게 찾을 수 있다.
Monolithic sorted map structure
모놀리식 정렬된 맵은 두 가지 기본 요소로 구성된다.
- System data : 클러스터에 있는 데이터의 위치를 설명하는 메타 범위를 포함한다.
- User data : 클러스터의 테이블 데이터를 저장한다.
Meta ranges
클러스터에 있는 모든 범위의 위치는 키 공간의 시작 부분에 있는 2단계 인덱스에 저장되며, 첫 번째 수준(meta1)은 두 번째 수준을, 두 번째 수준(meta2)는 클러스터의 데이터를 주소 지정하는 메타 범위로 알려져 있다.
이 2레벨 인덱스와 사용자 데이터는 트리로 시각화할 수 있으며, 루트는 meta1, 두 번째 레벨은 Meta2 트리의 잎은 사용자 데이터를 보관하는 range로 구성할 수 있다.
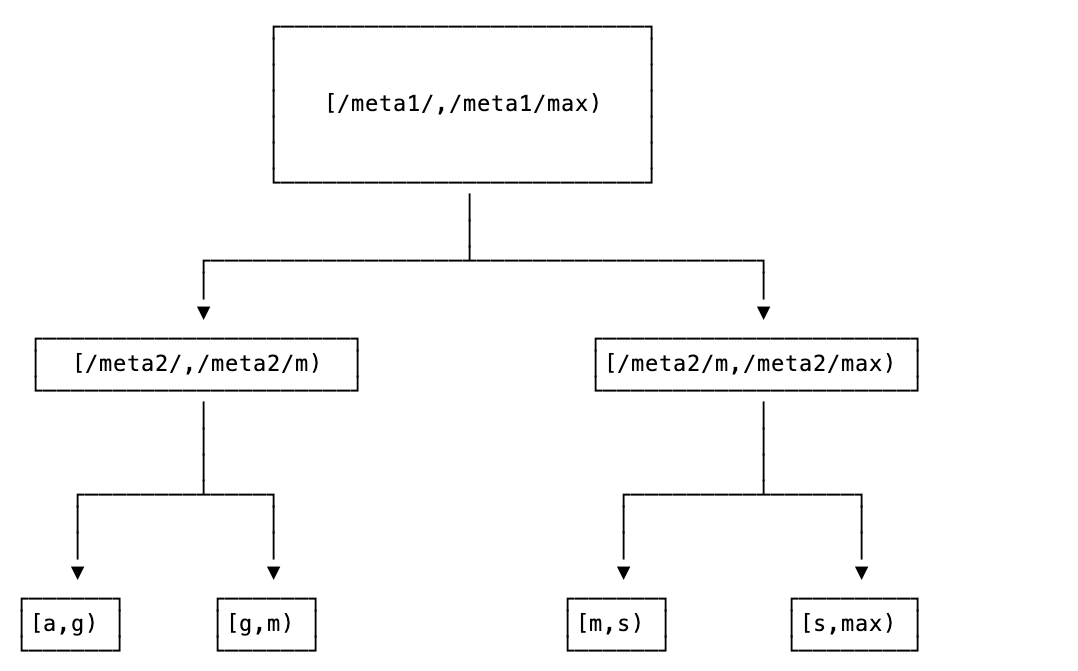
중요한 점은 모든 노드가 meta1 범위의 위치에 대한 정보를 가지고 있으며, range는 절대 분할되지 않다는 점이다.
이 메타 범위 구조는 기존적으로 최대 4EiB의 사용자 데이터를 처리할 수 있다. 그러나 범위 크기가 더 크면 이 용량 또한 확장 가능하다. 메타 범위는 대부분 일반 범위처럼 취급되며 클러스터의 다른 KV 데이터 요소와 마찬가지로 액세스 및 복제된다.
각 노드는 이전에 액세스한 meta2 범위의 값을 캐시해 향후 해당 데이터의 액세스를 최적화한다. 노드가 특정 키에 대해 meta2 캐시가 유효하지 않다는 것을 발견할 때마다 meta2 범위에 대한 정기적인 읽기를 수행해 캐시를 업데이트한다.
Table data
노드의 메타 범위 다음에는 클러스터가 저장하는 KV 데이터가 있다.
각 테이블과 그 보조 인덱스는 처음에 단일 범위에 매핑되며, 범위의 각 KV 쌍은 테이블의 단일 행 또는 보조 인덱스의 단일 행을 나타낸다. 범위가 기본 범위 크기에 도달하면 범위는 두 개의 범위로 분할된다. 이 프로세스는 테이블과 인덱스가 계속 증가함에 따라 계속 진행된다. 테이블이 여러 범위로 분할되면 테이블과 보조 인덱스가 별도의 범위에 저장될 가능성이 높다. 그러나 범위는 여전히 테이블과 보조 인덱스 모두에 대한 데이터를 포함할 수 있다.
기본 범위 크기는 노드 간에 빠르게 이동할 수 있을 만큼 작으면서도 키가 함께 액세스될 가능성이 높은 의미 있게 연속된 데이터 세트를 저장할 수 있을 만큼 큰 크기 사이의 최적점을 나타낸다. 그런 다음 이러한 범위는 생존 가능성을 보장하기 위해 클러스터에서 셔플된다.
이러한 테이블 범위는 적절한 이름의 복제 계층에서 복제되며, 각 복제본의 주소는 meta2 범위에 저장된다.
Using the monolithic sorted map
메타 범위 섹션에서 설명한 대로 클러스터에 있는 모든 범위의 위치는 2단계 인덱스에 저장된다.
- 첫 번째 수준(meta1)은 두 번째 수준을 가르킨다.
- 두 번째 수준(meta2)는 사용자 데이터를 다룬다.
노드가 요청을 받으면 이 트리의 잎부터 시작해 상향식 방향으로 요청에 포함된 키가 있는 범위의 위치를 찾는다. 이 프로세스는 다음과 같이 동작한다.
- 각 키에 대해 노드는 두 번재 수준의 범위 메타데이터(meta2)에서 지정된 키가 포함된 범위의 위치를 조회한다. 해당 정보는 성능을 위해 캐시되며 범위의 위치가 캐시에서 발견되면 즉시 반환된다.
- 범위의 위치가 캐시에서 발견되지 않으면 노드는 meta2의 실제 값이 있는 범위의 위치를 조회한다. 이 정보도 캐시되며, meta2 범위의 위치가 캐시에서 발견되면 노드는 meta2 범위로 RPC를 전송해 요청이 작동하려는 키의 위치를 가져온 다음 해당 정보를 반환한다.
- meta2 범위의 위치가 캐시에서 발견되지 않으면 노드는 범위 메타데이터의 첫 번째 수준(meta1)의 실제 값이 있는 범위의 위치를 조회한다. meta1의 위치는 가십 프로토콜을 사용해 클러스터의 모든 노드에 분산되어 있기 때문에 이 조회는 항상 성공한다. 그런 다음 노드는 meta1의 정보를 사용해 meta2의 위치를 조회하고 meta2에서 요청에 포함된 키가 포함된 범위의 위치를 조회한다.
위에서 설명한 프로세스는 재귀적이며, 조회가 수행될 때마다 1의 캐시에서 위치를 가져오거나, 2 트리의 다음 레벨 “위”에 있는 값에 대해 또 다른 조회를 수행한다는 점에 유의해라. 범위 메타데이터가 캐시되어 있기 때문에 일반적으로 다른 노드에 RPC를 보내지 않고도 조회를 수행할 수 있다.
이제 노드가 요청의 키가 있는 범위의 위치를 알았으므로, 요청의 KV 연산을 BatchRequest의 범위로 보낸다.
Interactions with other layers
- 같은 노드에 있는 트랜잭션 계층으로 부터 요청을 받음
- 요청을 수신해야 하는 노드를 식별한 다음 적절한 노드의 복제 계층으로 요청을 보냄