
What Is the Kappa Architecture?
카파 아키텍처는 스트리밍 데이터를 처리하는데 사용되는 소프트웨어 아키텍처다. 카파 아키텍처의 기본 전제는 “단일 기술 스택”으로 실시간 처리와 일괄 처리, 특히 분석을 모두 수행할 수 있다는 것이다. 이 아키텍처는 수신되는 일련의 데이터가 먼저 Kafka와 같은 메세징 엔진에 저장되는 스트리밍 아키텍처를 기반으로 한다. 거기서부터 스트림 처리 엔진이 데이터를 읽고 분석 가능한 형식으로 변환한 다음, 최종 사용자가 쿼리할 수 있도록 분석 데이터베이스에 저장한다.
카파 아키텍처는 데이터가 메세징 엔진에 삽입된 직후 데이터를 읽고 변환할 때 준실시간에 가까운 분석을 지원한다. 따라서 최종 사용자가 쿼리할 때 최신 데이터를 신속하게 사용할 수 있다. 또한 나중에 메세징 엔진에서 저장된 스트리밍 데이터를 일괄적으로 읽어들여 더 많은 유형의 분석을 위한 분석 가능한 추가 출력을 생성함으로써 과거 분석을 지원한다.
카파 아키텍처는 동일한 기술 스택을 사용해 실시간 스트림 처리와 historical 배치 처리를 지원하기 때문에 람다 아키텍처에 비해 더 간단한 대안으로 간주된다. 두 아키텍처 모두 대규모 분석을 가능하게 하는 히스토리 데이터의 저장을 수반한다. 두 아키텍처 모두 처리 코드의 문제(버그 등)을 해결하기 위해 코드를 업데이트하고 히스토리 데이터에서 다시 실행해 “human fault tolerance”를 극복하는데도 유용하다. 카파 아키텍처의 큰 차이점은 모든 데이터가 스트림처럼 취급되므로 스트림 처리 엔진이 유일한 데이터 변환 엔진으로 작동한다는 점이다.
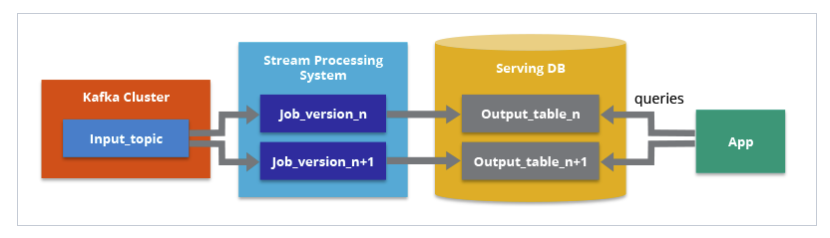
What Is a Streaming Architecture?
스트리밍 아키텍처는 데이터가 생성되는 시점에 일련의 데이터에 대해 작업을 수행하는 방식인 스트림 처리를 위해 함께 작동하는 정의된 기술 집합이다. 최근의 많은 기술 스택에서 Kafka는 스트리밍 데이터의 저장소 역할을 하며, 여러 스트림 프로세서가 Kafka에 저장된 데이터를 처리해 여러 출력을 생성할 수 있다. 일부 스트리밍 아키텍처에는 스트림 처리와 배치 처리를 위한 워크플로가 모두 포함되어 있는데, 대규모 배치 처리를 처리하기 위해 다른 기술을 사용하거나 카파 아키텍처에 명시된 대로 카프카를 중앙 저장소로 사용한다.
How Do the Kappa and Lambda Architectures Compare?
두 아키텍처 모두 단일 환경에서 실시간 분석과 히스토리 분석을 처리한다. 그러나 람다 아키텍처에 비해 카파 아키텍처의 주요 이점 중 하나는 스트리밍과 배치 처리 시스템을 단일 기술로 구축할 수 있다는 점이다. 즉, 실시간 데이터를 처리하는 스트림 처리 애플리케이션을 구축한 후 출력을 수정해야 하는 경우 코드를 업데이트한 다음 메세징 엔진의 데이터에 대해 일괄 처리 방식으로 다시 실행할 수 있다. 람다 아키텍처에서 제안하는 것처럼 배치 프로세싱을 처리하기 위한 별도의 기술은 업다.
헤이즐캐스트 플랫폼과 같이 충분히 빠른 스트림 처리 엔진이 있다면 일괄 처리에 최적화된 별도의 기술이 필요하지 않을 수도 있다. 저장된 스트리밍 데이터 파이프라인을 병렬로 읽고 데이터를 스트리밍 소스에서 가져온 것처럼 변환하기만 하면 된다. 일부 환경에서는 필요에 따라 분석 가능한 출력을 생성할 수 있으므로 최종 사용자로부터 새로운 쿼리가 제출되면 해당 쿼리에 최적으로 답할 수 있도록 데이터를 임시로 변환할 수 있다. 제일 중요한 것은 이를 위해 처리 지연 시간을 단축할 수 있는 “고속 스트림 처리 엔진”이 필요하다.
람다 아키텍처는 반드시 사용해야 하는 기술을 지정하지 않았지만, 일괄 처리 구성 요소는 종종 하둡과 같은 대규모 데이터 플랫폼에서 수행된다. HDFS(Hadoop Distributed File System)은 원시 데이터를 경제적으로 저장할 수 있으며, 그 후 하둡 도구를 통해 분석 가능한 형식으로 변환할 수 있다. 시스템의 일괄 처리 구성 요소에는 하둡이 사용되지만, 실시간 분석 구성 요소에는 스트림 처리용으로 설계된 별도의 엔진이 사용된다. 그러나 람다 아키텍처의 한가지 장점은 대규모 기록 분석을 위해 더 큰 데이터 세트(PB range)를 하둡에서 더 효율적으로 저장하고 처리할 수 있다는 것이다.