
Improved Location Caching with Quadtrees
초당 수천 건의 요청을 처리하는 웹 서비스를 구축하려면 좋은 캐싱 전략이 필요하다. 하지만 지리적 위치가 이러한 요청의 주요 매개변수인 경우, 기존 캐싱 전략은 제대로 동작하지 않는다. 이번 포스트는 지리적 위치를 캐싱하는 다양한 접근 방식과 상대적 장단점을 살펴본다.
Background
Xone이라는 애플리케이션은 사용자의 지리적 위치를 기반으로 주변의 비즈니스 목록을 제공한다.
1 | GET /nearbyBusinesses?latitude=40.741111&longitude=-73.987448 |
이 엔드포인트는 지정된 위치 근처의 최대 20개의 비즈니스를 반환한다.
1 | { |
Xone 백엔드는 피크 시간에 초당 4000건 이상의 요청을 받으므로 모든 요청에 대한 결과를 계산하려면 데이터 베이스에 부하가 빠르게 걸리게 된다. 다행히 많은 검색이 비슷한 위치에서 발생하고 동일한 응답을 받는다. 최근에 계산한 응답을 캐시해두었다가 비슷한 요청이 들어올 때 재사용함으로 처리 능력과 시간을 많이 절약할 수 있다.
Basic caching
대부분의 웹 서버는 캐싱을 사용해 이전에 계산한 결과를 임시로 저장하여 반복 작업을 수행하지 않도록 한다. 다음은 블로그 서버가 각각의 포스트를 캐싱하는 한 예이다.
1 | public static void getPost(int postId) { |
이런 전략을 Xone 백엔드에 적용하려 한다면 캐시 조회는 아래와 같다.
1 | List<Result> results = |
이 방식의 문제는 위도와 경도가 너무 세분화되어 있어 캐시 히트율이 떨어진다는 점이다.
Tiles and grids
위치 좌표를 처리하는 것은 데이터 소스가 본질적으로 부정확할 수 있기 때문에 어렵다. 위치 판독값의 변동성이 크기 때문에 사용자는 움직이지 않아도 요청마다 다른 추정치를 얻을 수 있다. 그러나 정확한 위치를 보고하더라도 위치 좌표를 캐싱하는 것은 문제가 있다. 사용자는 (40.74120, -73.98679) 에서 (40.74124, -73.98676)로 좌표가 변할 수 있지만 애플리케이션에서는 의미 있는 차이가 아니다.
이 문제를 해결하는 가장 쉬운 전략은 위도 및 경도 값의 정밀도를 낮추는 것이다. 아래는 좌표를 소수점 이하 3자리로 잘라 만든 그리드의 시각화이다.
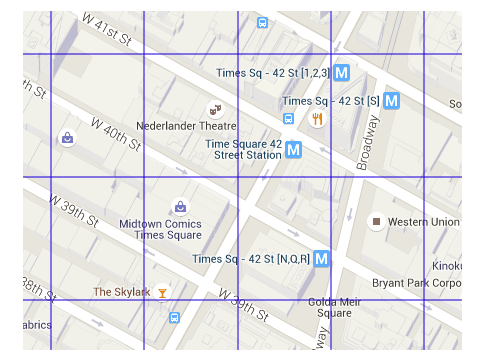
격자 셀은 약 100m * 100m로 모든 좌표를 나타낸다. 정밀도가 낮은 위치 좌표를 사용하면 일반적으로 작은 위치 변경에도 동일한 캐시 키에 매핑된다.
1 | String cacheKey = String.format("businesses-%.03f-%.03f", lat, lng); |
Grid accuracy
소수점 이하 3자리를 잘라낸 뒤 캐시 적중률은 5% 에서 18%로 개선되었다. 다양한 정밀도 수준을 측정한 결과 아래와 같은 결과를 얻을 수 있다.
| DECIMAL PLACES | CELL SIZE | CACHE HIT RATIO |
|---|---|---|
| 3 (e.g., 40.741, -73.986) | 100m | 18% |
| 2 (e.g., 40.74, -73.98) | 1km | 65% |
| 1 (e.g., 40.7, -73.9) | 10km | 95% |
정밀도를 낮추면서 캐시 히트율은 높아졌지만, 멀리 떨어진 두 사용자가 근처에 20개의 동일한 비즈니스 목록을 응답받는 문제가 생긴다. 검색 결과에서 사용자와 더 가까운 비즈니스가 제외되지 않는 경우를 결과 집합이 유효하다고 정의한다. 하지만 이 경우엔 셀을 나누는 방식이 거칠기 때문에 결과가 유효하지 않게 되었다.
Dynamic Grids
셀의 크기가 10km나 되면 도시 지역에서는 사용하기 힘들지만, 도시 외곽이나 밀집도가 낮은 지역에서는 충분히 합당하다. 이상적으로는 인구 밀도가 낮은 지역에서는 크고 부정확한 셀을, 인구 밀도가 높은 지역에서는 더 작고 세분화된 셀을 사용할 수 있다.
쿼드트리는 2차원 공간을 적응 가능한 셀로 인코딩하는 데이터 구조다. 이진트리와 유사하게 쿼드트리는 잎이 아닌 모든 노드에 4개의 자식이 있는 트리구조다. 위치 맥락에서 이는 NW, NE, SW, SE의 사분면으로 나뉜다. 각 쿼드트리의 노드는 재귀적으로 세분화될 수 있고 단계를 거칠수록 셀이 더 작아진다.
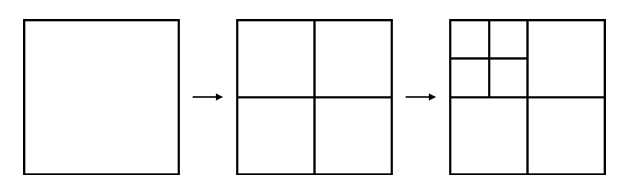
쿼드트리는 사용하면 결과의 정확도와 유효성 사이에 균형을 맞출 수 있다. 개념적으로는 각 리프 노드가 충분히 정밀해 해당 노드에서 어떤 위치를 검색해도 동일한 비즈니스 집합을 찾을 수 있는 트리를 구축한다 가정하자. 이를 위해 전 세계를 대표하는 단일 노드에서 시작해 각 노드가 이 기준을 충족할 때 까지 필요에 따라 트리를 세분화 한다.
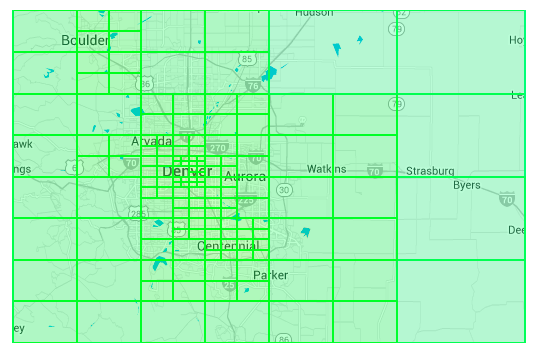
이 이미지의 각 사각형은 생성된 쿼드트리의 리프 노드를 나타내며 해당 범위 내의 모든 위치에는 동일한 인근 비즈니스 집합이 있다는 속성을 가진다.
매일 현재 진행중인 비즈니스를 기반으로 쿼드트리를 재계산하고, 일관된 검색 결과의 주요 기준을 충종하기 위한 간단한 휴리스틱을 사용한다. 노드 중심으로 한 검색 결과의 수가 임계값을 초과하는 경우, 노드를 세분화 한다.
1 | public static void buildQuadtree(Node node) { |
이 알고리즘은 고정된 검색 반경을 사용하는 대신 쿼드트리 노드의 크기에 비례하는 반경으로 검색한다. 이렇게 하면 캐시의 모든 항목에 비슷한 수의 검색 결과가 표시되도록 보장하는 동시에 검색 결과가 여전히 유효하는 것을 보장할 수 있다.
Quadtrees in action
서버에서 특정 위치 근처의 비즈니스에 대한 요청을 받으면 먼저 해당 위치의 쿼드트리 노드를 조회한 후 해당 노드를 캐시 키를 구축하는데 사용하고 필요한 경우 비즈니스 검색에 사용한다.
1 | public static void getNearbyBusinesses(float latitude, float longitude) { |
캐시 미스일때 수행되는 검색은 캐시 트리를 구축할 때 수행되는 검색과 동일하며, 노드 크기에 비례하는 반경으로 노드를 중심으로 검색이 수행된다.
Results
쿼드트리를 사용하면 높은 정밀도와 낮은 정밀도를 모두 갖춘 지리적 위치 캐싱의 장점을 결합할 수 있다. 위치를 기반으로 요청을 캐싱하는 것은 크고 지속적으로 변화하는 키 공간으로 인해 표준 캐싱의 어려움이 가중되는 까다로운 문제다. 쿼드트리는 지리적 분포에 따라 캐시된 결과의 세분성을 변경할 수 있도록 하여 문제를 단순화 한다.