
Redis ZSET과 LIST
진행중인 프로젝트에서 어뷰징 탐지를 위해 Redis를 검토하며 정리한 내용입니다
부족한 부분에 대한 지적은 감사히 받겠습니다!
개요
어뷰징 탐지를 위해 최근 t 시간동안 k번의 요청이 들어온다면 해당 유저를 b 시간동안 블락시켜야 한다. RDB로도 충분히 구현할 수 있는 스펙이지만 최근 t 시간이 전에 들어온 요청들은 쓸모가 없어지니 삭제해주어야 한다. RDB로 구현하기보다 Redis를 사용해서 스펙을 구현하게끔 설계를 했다.
어떻게 구현할 것인가?
최근 t 시간동안 n번의 요청
스펙 구현을 위해 검토한 자료구조는 List와 ZSet이다. 먼저 List부터 알아보자.
List
LinkedList 처럼 LIFO FIFO 구현이 모두 가능한 자료구조이다. List를 사용해서 구현할 시에는 최근 t 시간이라는 문맥보다 k번의 요청에 중점을 두어야 한다. 즉 List의 마지막 k 번째 엔트리의 timeStamp의 값을 최근 t 시간과 비교해 유저를 블락시킬지 처리할 수 있다. 즉 시간 복잡도는 O(k)에 수렴한다.
List는 Redis 내에서 Zip List Linked List Quick List 세 가지 자료구조로 관리 된다.
Zip List
Zip List의 자료 구조는 다음과 같다.
- zlbytes : 짚 리스트의 총 바이트 수
- zltail : 마지막 엔트리의 시작 지점
- zllen : 짚 리스트 총 엔트리 수
- zlen : 짚 리스트의 끝을 나타내는 바이트
각각의 엔트리는 다음과 같이 구현이 되어 있다.
- prevlen : 이전 엔트리의 길이 (역방향 탐색에 사용됨)
- itself len : 현재 엔트리의 길이
- value : 값
그림에서 이해할 수 있듯이 각각의 엔트리는 메모리 구조상 연속된 공간에 할당되어 있다. 그러다 보니 엔트리의 수가 많아지면 fragmentation이 발생하게 되는 구조이다.
Linked List
Linked List는 Double Linked List로 구현이 되어 있다.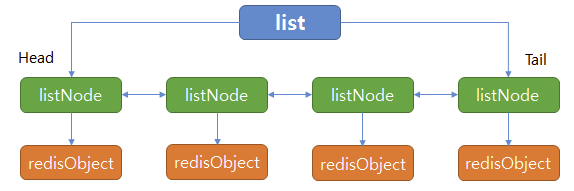
각 엔트리의 prev 와 next가 포인터로 연결되어 있는 구조다 보니 fragmentation에 대한 걱정은 ZipList보다 적다.
Redis에 별도의 튜닝을 하지 않았다면 다음과 같은 설정 값에서 Zip List는 Linked List로 전환된다.
1 | list-max-ziplist-entries 512 |
Quick List
Quick List는 Zip List와 Linked List를 조합한 자료구조이다. 하나의 큰 Linked List에서 각 엔트리의 value는 하나의 Zip List를 가지고 있는 구조이다. 매우매우 큰 리스트 데이터를 처리하기에 적합한 구조로 되어있다.

ZSet
ZSet은 Sorted List를 구현하는 자료구조이다. Score로 정렬에 평가될 값을 판단하게 된다. ZSet을 사용해서 스펙을 구현하게 될 경우 최근 t 시간이라는 문맥에 집중하면 유저의 어뷰징 여부를 판단할 수 있다. 정렬된 상태로 존재하게 되니 최근 t 시간이라는 값을 탐색을 수행해서 O(log(n))의 시간에 탐색을 완료할 수 있게된다.
ZSet은 내부적으로 Zip List와 Skip List로 구현이 나뉘게 된다.
Zip List
Zip List의 기본적인 개념은 위에서 다루었으니, Sorted List를 위한 Zip List에 내용만을 서술한다. 새로운 값이 삽입될 위치를 찾아야 하니 Zip List로 구현된 ZSet에는 최대 O(n)의 시간이 걸리게 된다. 거기에 새로운 값을 할당하기 위해 새로운 Zip List를 malloc() 하고 memmove()를 수행하면 시간은 그에 비해 더 늘어나게 된다.
Skip List
Skip List는 기본적으로 List의 엔트리를 스킵할 수 있는 개념을 차용해서 만들어진 자료구조이다. 선형적인 탐색을 한다는 개념은 같지만, 한번에 하나의 엔트리씩 모든 엔트리를 찾아가는게 아닌, 적절한 위치를 탐색할 때 까지 여러개의 엔트리를 건너뛴다. 몇 개의 엔트리를 건너뛸 지는 Skip List의 레벨에 따라 달리지게 되는데, 이 레벨은 Skip List에 엔트리가 삽입될 때 마다 각 엔트리의 레벨이 평가되 삽입되게 된다. 따라서 위에서 언급한 ZSet의 O(log(n))의 시간 복잡도가 나오게 된다.

어떤것을 선택할 것인가?
현재 스펙에 따르면 List로 구현을 해도 Zip List의 자료구조를 사용하게 될 것이고 ZSet으로 구현을 해도 Zip List를 사용하게 될 확률이 매우 높았다. 상세 스펙을 제시할 순 없지만 수학적으로 계산을 해 보았을 때, O(n)보다 O(k)의 값이 작았기에 List로 구현하는 것이 시간적으로는 적합하다고 계산할 수 있었다. 다만 몇가지 고민을 하다 보니 ZSet이 더 적합하다는 결론에 도달했다. 그 이유는 다음과 같다.
- 최적화를 수행하면 ZSet의
O(n)을O(k)로 수렴시킬 수 있다. - Zip List에서 Skip List나 Linked List로의 변경이 일어났을 때 되돌아 갈 수 없다.
첫번째 최적화인 케이스이다. List를 사용하게 될 경우 O(k)는 역순으로 탐색해 k번째 노드에 도착하기 때문에 다음과 같은 시간 복잡도가 나오게 된다. 다만 최근 t 시간이 지난 데이터를 제거하고, 이미 유저가 어뷰저로 판명이 되었을 때 새로운 값을 넣지 않게 설계를 한다고 하면 전체 엔트리 개수인 n을 k로 수렴시킬 수 있다.
두번째 Zip List에서의 변환이다. 사실 Zip List를 사용하기에는 두 조건이 붙는다. 첫째는 엔트리 개수의 제한이다.(k 의 값이 엔트리 개수보다 적어 Zip List가 다른 자료구조로 변환될 가능성은 매우 적다) 두번째는 엔트리 value size이다. 하나의 엔트리라도 기준값을 넘어가게 되면 Zip List는 다른 자료구조로 바뀌게 되고, 다시는 Zip List로 돌아오지 않는다. 그렇게 된다면 ZSet을 사용하게 될 경우 O(log(k))의 시간 복잡도를 만들어 낼 수 있게 된다.
b 시간동안 사용자 접근 금지 처리
사실 이 부분은 매우 간단한 부분이다. Redis가 캐시 기능을 수행한다는 점을 생각하면 된다. 즉 어뷰저로 판단된 유저가 생기면 새로운 key를 생성해서 expire user for b times를 수행하면 된다. 접근 금지 처리가 되었는지는 key의 존재 유무로 확인하면 되니 간단한 작업이다.
마치며
재미있는 스펙을 구현하면서 Redis가 어떻게 동작하는가를 좀 더 자세히 들여볼 수 있는 기회였다.