병렬 스트림 스트림에서는 parallelStream()을 통해 손쉽게 작업을 병렬로 처리할 수 있다. 또한 parallel()이나 sequential()로도 병렬 혹은 순차 스트림으로 중간에 변경이 가능하다. 하지만 이는 내부적으로 병렬 혹은 순차 스트림 여부를 나타내는 boolean 값을 변경해주는데 의미가 있는 동작으로 전체적인 동작 여부는 마지막에 호출된 스트림 동작 방식에 의해 결정된다.
다음 코드를 실행해보면 확실히 이해할 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 List<Integer> integers = Stream.iterate(1 , i -> i + 1 ).limit(10 ).collect(Collectors.toList()); integers.stream() .filter(integer -> { System.out.println("first predicate with " + integer); return true ; }) .parallel() .filter(integer -> { System.out.println("second predicate with " + integer); return true ; }) .sequential() .filter(integer -> { System.out.println("third predicate with " + integer); return true ; }) .collect(Collectors.toList());
병렬로 작업을 처리한다고 순차 스트림보다 실행속도가 향상된다는것을 무조건 보장할 수는 없다. 다음은 코드를 실행 시킨 결과다
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 private static final long N = 10000000 ;private void streamIterateSequential () { getTime((t) -> { return t.reduce(0L , Long::sum); }, Stream.iterate(1L , i -> i + 1 ).limit(N)); } private void streamIterateParallel () { getTime((t) -> { return t.reduce(0L , Long::sum); }, Stream.iterate(1L , i -> i + 1 ).limit(N).parallel()); } private void longStreamSequential () { getTime((t) -> { return t.reduce(0L , Long::sum); }, LongStream.rangeClosed(1 , N)); } private void longStreamParallel () { getTime((t) -> { return t.reduce(0L , Long::sum); }, LongStream.rangeClosed(1 , N).parallel()); } private <T, R> R getTime (Function<T, R> function, T t) { R result = function.apply(t); return result; }
1 2 3 4 streamIterateSequential Takes 387(ms) streamIterateParallel Takes 1458(ms) longStreamSequential Takes 19(ms) longStreamParallel Takes 16(ms)
Stream.iterate가 대체적으로 느린 이유는 박싱 언박싱과 관련이 있다. 그리고 Stream.iterate에서 병렬 수행이 더 늦게 나타난 이유는 반복 작업이 병렬로 수행할 수 있는 독립 단위로 나누기 어렵기 때문이다. 그와 반대로 LongStream에서는 박싱 비용이 없고 쉽게 청크로 분할 가능한 숫자 범위를 생성하기 때문에 위와 같은 결과가 나타난다.
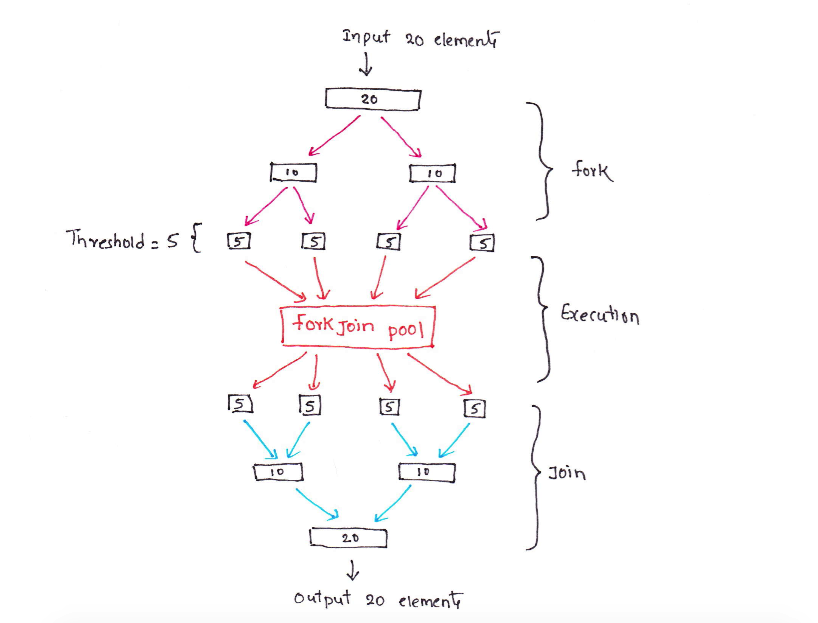
Fork Join 프레임워크 Stream의 병렬 처리는 Fork Join 프레임워크로 처리된다. Fork Join 프레임워크는 작업을 재귀적으로 분할하고 서브태스크의 결과를 합쳐 전체 결과를 만들 수 있도록 설계되었다.
또한 Frok Join 프레임워크는 작업 훔치기 라는 방법으로 작게 나누어진 Task들을 스레드가 유휴상태에 있지 않고 Task를 처리하도록 만든다. 이 기법을 통해 Task를 코어 개수와 관계 없이 적절한 크기로 Fork 하도록 하는게 이상적인 분할 방법이 되게 한다. Fork Join 프레임워크를 사용하기 위해선 ForkJoinTask에 작업을 할당해야 하는데 이미 구현된 추상 클래스들을 확장해서 사용하면 된다.
RecursiveAction : 작업을 수행하나 반환값이 없음 RecursiveTask : 작업을 수행하고 결과값을 반환 함
다음은 RecursiveTask로 피보나치 수열을 계산한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class FibonacciTask extends RecursiveTask <Integer> { private final int n; public FibonacciTask (int n) { this .n = n; } @Override protected Integer compute () { if (n <= 1 ) { return n; } FibonacciTask f1 = new FibonacciTask (n - 1 ); f1.fork(); FibonacciTask f2 = new FibonacciTask (n - 2 ); return f2.compute() + f1.join(); } }
Spliterator Spliterator는 분할 가능한 반복자이다. 주요 인터페이스 구성은 다음과 같다.
1 2 3 4 5 6 public interface Spliterator <T> { boolean tryAdvance (Consumer<? super T> action) ; Spliterator<T> trySplit () ; long estimateSize () ; int characteristics () ; }
tryAdvance : 수행해야할 작업을 수행하며 작업 대상에 대한 요소가 남아있다면 TRUE를 반환한다.trySplit : 분할할 수 있는 단계까지 요소를 분할한다. 더 이상 분할할 수 없으면 null을 반환한다.estimateSize : 탐색해야할 요소의 수에 대해 반환한다.characteristics : Spliterator의 특성에 대해 표현한다.
ORDERED, DISTINCT, SORTED, SIZED, NON-NULL, IMMUTABLE, CONCURRENT, SUBSIZED
다음은 배열에 Spliterator가 가능하도록 만든 코드이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public class ArraySpliterator <T> implements Spliterator <T> { private final T[] elements; private final int THRESHOLD = 5 ; private int index = 0 ; public ArraySpliterator (T[] elements) { this .elements = elements; } @Override public boolean tryAdvance (Consumer<? super T> action) { action.accept(elements[index++]); return index < elements.length; } @Override public Spliterator<T> trySplit () { int remainElements = elements.length - index; if (remainElements <= THRESHOLD) { return null ; } T[] newArray = Arrays.copyOfRange(elements, index, Math.min(elements.length, index + THRESHOLD)); this .index = Math.min(elements.length, index + THRESHOLD); return new ArraySpliterator (newArray); } @Override public long estimateSize () { return elements.length - index; } @Override public int characteristics () { return ORDERED + SIZED + SUBSIZED + NONNULL + IMMUTABLE; } }
1 2 3 4 Integer[] integers = IntStream.rangeClosed(0 , 100 ).boxed().toArray(Integer[]::new ); Spliterator<Integer> spliterator = new ArraySpliterator (integers); Stream<Integer> stream = StreamSupport.stream(spliterator, true ); System.out.println(stream.reduce(0 , Integer::sum, Integer::sum));